Spreadsheet Form Element อนุญาตให้ผู้ใช้ดำเนินการหลายอย่างในสภาพแวดล้อมที่เหมือน excel ขึ้นอยู่กับกรณีการใช้งาน ตัวอย่างการใช้สเปรดชีตคือ:
- การแก้ไขฐานข้อมูล
การควบคุมการกำหนดค่าการรวมข้อมูลการวางแผนทรัพยากรบุคคลการรายงานการขายการวิเคราะห์ทางการเงิน
ฟีเจอร์นี้เป็นคุณสมบัติใหม่ใน joget Workflow เว่อร์ชั่น 6

ภาพที่ 1 : ภาพตัวอย่างแสดงแผ่นตารางทำการในมุมมองผู้ใช้งาน

Figure 2 : คุณสมบัติแผ่นตารางทำการ
| Name | Description | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Spreadsheet | รหัสตารางทำการ | ||||||||||||||||
| Label | หัวข้อแผ่นตารางทำการ | ||||||||||||||||
| Columns | คอลัมน์แผ่นตารางทำการถูกกำหนดที่นี่
|
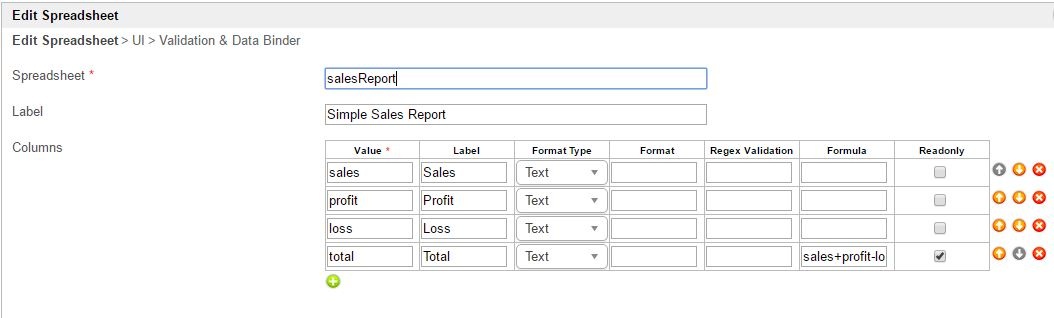

ภาพที่ 3 : คุณสมบัติแผ่นตารางทำการ - หน้าจอผู้ใช้งาน
| Name | Description |
|---|---|
| Enable Header Sorting? | กำหนดว่าผู้ใช้สามารถเรียงลำดับข้อมูลแผ่นตารางทำการตามคอลัมน์ |
| Data Order Field ID | ข้อมูลที่จะให้ขึ้นตามฟิลด์ จะต้องสอดคล้องกับรหัสฟิลด์ในแบบฟอร์มเป้าหมาย |
| Readonly | กำหนดว่าแผ่นตารางทำการทั้งหมดสามารถแก้ไขได้หรือไม่ |
| Disable Add Feature | พิจารณาว่าสามารถเพิ่มแถวใหม่ได้หรือไม่ |
| Disable Delete Feature | พิจารณาว่าสามารถลบแถวได้หรือไม่ |
| Show Row Numbering? | แสดงคอลัมน์เพิ่มทางด้านซ้ายสุดเพื่อแสดงหมายเลขSample หมายเลขแถว
|
| Number of columns to fixed on left | อนุญาตให้ระบุจำนวนคอลัมน์ที่ไม่เปลี่ยน (หรือค่ามั่นคง) ทางด้านซ้ายของตาราง ค่าเริ่มต้น: 0 |
| Number of spare rows | จำนวนแถวว่างที่จะเพิ่มโดยอัตโนมัติหลังจากบรรทัดที่มีค่าข้อมูล Sample แถวว่าง 1 แถว
|
| Custom Settings (JSON) | - |


ภาพที่ 4 : คุณสมบัติแผ่นตารางทำการ - การตรวจสอบและตั้งค่าให้สมบูรณ์
| Name | Description |
|---|---|
| Validator | แนบปลั๊กอิน Validator เพื่อตรวจสอบความถูกต้องของค่าที่ป้อนเข้ามา โปรดดูที่ ตรวจสอบข้อมูลของฟอร์ม (Form Validator). When will validation takes place? การตรวจสอบจะเกิดขึ้นทุกครั้งที่มีการบันทึกแบบฟอร์มยกเว้นเมื่อบันทึกเป็น "Save as Draft" |
| Min Number of Row Validation (Integer) | กำหนดจำนวนแถวขั้นต่ำที่จำเป็นสำหรับการป้อนข้อมูล |
| Max Number of Row Validation (Integer) | กำหนดจำนวนแถวสูงสุดที่เป็นไปได้สำหรับอินพุต |
| Error Message | ข้อความแสดงข้อผิดพลาดที่จะแสดงเมื่อไม่ตรงตามข้อกำหนดของแถวที่ตั้งไว้ข้างต้น |
| Load Binder | ตัวเลือกโดยค่าเริ่มต้น ข้อมูลจะถูกบันทึก / โหลดในรูปแบบ JSON ในฐานข้อมูลที่กำหนดไว้ |
| Store Binder | ตัวเลือกโดยค่าเริ่มต้น ข้อมูลจะถูกบันทึก / โหลดในรูปแบบ JSON ในฐานข้อมูลที่กำหนดไว้ |
ฟังก์ชั่นสูตรที่รองรับ
สูตรแผ่นตารางทำการนำไปใช้กับฟังก์ชันสูตร Excel บางส่วนดังนี้ โปรดอ้างอิง Excel Formula Functions .
ABS(number)
ACOS(number)
ACOSH(number)
ACOT(number)
ACOTH(number)
ADD(num1, num2)
AGGREGATE(function_num, options, ref1, ref2)
AND(logical1, [logical2], ...)
ARABIC(text)
ARGS2ARRAY(arg1, [arg1], ...)
ASIN(number)
ASINH(number)
ATAN(number)
ATAN2(number_x, number_y)
ATANH(number)
AVEDEV(number1, [number2], ...)
AVERAGE(number1, [number2], ...)
AVERAGEA(number1, [number2], ...)
BASE(number, radix, min_length)
BESSELI(x, n)
BESSELJ(x, n)
BESSELK(x, n)
BESSELY(x, n)
BETA.DIST(x, alpha, beta, cumulative, A, B)
BETA.INV(probability, alpha, beta, A, B)
BETADIST(x, alpha, beta, cumulative, A, B)
BETAINV(probability, alpha, beta, A, B)
BIN2DEC(number)
BIN2HEX(number, places)
BIN2OCT(number, places)
BINOM.DIST(successes, trials, probability, cumulative)
BINOM.DIST.RANGE(trials, probability, successes, successes2)
BINOM.INV(trials, probability, alpha)
BINOMDIST(successes, trials, probability, cumulative)
BITAND(number1, number2)
BITLSHIFT(number, shift)
BITOR(number1, number2)
BITRSHIFT(number, shift)
BITXOR(number1, number2)
CEILING(number, significance, mode)
CEILINGMATH(number, significance, mode)
CEILINGPRECISE(number, significance, mode)
CHAR(number)
CHISQ.DIST(x, k, cumulative)
CHISQ.DIST.RT(x, k)
CHISQ.INV(probability, k)
CHISQ.INV.RT(p, k)
CHOOSE(index_num, value1, [value2], ...)
CLEAN(text)
CODE(text)
COMBIN(number, number_chosen)
COMBINA(number, number_chosen)
COMPLEX(real, imaginary, suffix)
CONCATENATE(arg1, [arg1], ...)
CONFIDENCE(alpha, standard_dev, size)
CONFIDENCE.NORM(lpha, standard_dev, size)
CONFIDENCE.T(lpha, standard_dev, size)
CONVERT(number, from_unit, to_unit)
CORREL(array1, array2)
COS(number)
COSH(number)
COT(number)
COTH(number)
COUNT(arg1, [arg1], ...)
COUNTA(arg1, [arg1], ...)
COUNTBLANK(arg1, [arg1], ...)
COUNTUNIQUE(arg1, [arg1], ...)
COVARIANCE.P(array1, array2)
COVARIANCE.S(array1, array2)
CSC(number)
CSCH(number)
CUMIPMT(rate, periods, value, start, end, type)
CUMPRINC(rate, periods, value, start, end, type)
DATE(year, month, day)
DATEVALUE(date_text)
DAY(serial_number)
DAYS(end_date, start_date)
DAYS360(start_date, end_date, method)
DB(cost, salvage, life, period, month)
DDB(cost, salvage, life, period, factor)
DEC2BIN(number, places)
DEC2HEX(number, places)
DEC2OCT(number, places)
DECIMAL(number, radix)
DEGREES(number)
DELTA(number1, number2)
DEVSQ(number1, [number2], ...)
DIVIDE(dividend, divisor)
DOLLAR(number, decimals)
DOLLARDE(dollar, fraction)
DOLLARFR(dollar, fraction)
E()
EDATE(start_date, months)
EFFECT(rate, periods)
EOMONTH(start_date, months)
EQ(value1, value2)
ERF(lower_bound, upper_bound)
ERFC(x)
EVEN(number)
EXACT(text1, text2)
EXPON.DIST(x, lambda, cumulative)
EXPONDIST(x, lambda, cumulative)
F.DIST(x, d1, d2, cumulative)
F.DIST.RT(x, d1, d2)
F.INV(probability, d1, d2)
F.INV.RT(p, d1, d2)
FACT(number)
FACTDOUBLE(number)
FALSE()
FDIST(x, d1, d2, cumulative)
FDISTRT(x, d1, d2)
FIND(find_text, within_text, position)
FINV(probability, d1, d2)
FINVRT(p, d1, d2)
FISHER(x)
FISHERINV(y)
FIXED(number, decimals, no_commas)
FLOOR(number, significance)
FORECAST(x, data_y, data_x)
FREQUENCY(data, bins)
FV(rate, periods, payment, value, type)
FVSCHEDULE(principal, schedule)
GAMMA(number)
GAMMA.DIST(value, alpha, beta, cumulative)
GAMMA.INV(probability, alpha, beta)
GAMMADIST(value, alpha, beta, cumulative)
GAMMAINV(probability, alpha, beta)
GAMMALN(number)
GAMMALN.PRECISE(x)
GAUSS(z)
GCD(GCD)
GEOMEAN(number1, [number2], ...)
GESTEP(number, step)
GROWTH(known_y, known_x, new_x, use_const)
GTE(num1, num2)
HARMEAN(number1, [number2], ...)
HEX2BIN(number, places)
HEX2DEC(number)
HEX2OCT(number, places)
HOUR(serial_number)
HTML2TEXT(value)
HYPGEOM.DIST(x, n, M, N, cumulative)
HYPGEOMDIST(x, n, M, N, cumulative)
IF(test, then_value, otherwise_value)
IMABS(inumber)
IMAGINARY(inumber)
IMARGUMENT(inumber)
IMCONJUGATE(inumber)
IMCOS(inumber)
IMCOSH(inumber)
IMCOT(inumber)
IMCSC(inumber)
IMCSCH(inumber)
IMDIV(inumber1, inumber2)
IMEXP(inumber)
IMLN(inumber)
IMLOG10(inumber)
IMLOG2(inumber)
IMPOWER(inumber, number)
IMPRODUCT(inumber1, inumber2, ...)
IMREAL(inumber)
IMSEC(inumber)
IMSECH(inumber)
IMSIN(inumber)
IMSINH(inumber)
IMSQRT(inumber)
IMSUB(inumber1, inumber2)
IMSUM(inumber1, inumber2, ...)
IMTAN(inumber)
INT(number)
INTERCEPT(known_y, known_x)
INTERVAL(second)
IPMT(rate, period, periods, present, future, type)
IRR(values, guess)
ISBINARY(number)
ISBLANK(value)
ISEVEN(number)
ISLOGICAL(ISNONTEXT)
ISNONTEXT(ISNONTEXT)
ISNUMBER(value)
ISODD(number)
ISOWEEKNUM(date)
ISPMT(rate, period, periods, value)
ISTEXT(value)
JOIN(array, separator)
KURT(number1, [number2], ...)
LCM(number1, [number2], ...)
LEFT(text, number)
LEN(text)
LINEST(data_y, data_x)
LN(number)
LOG(number, base)
LOG10(number)
LOGEST(data_y, data_x)
LOGNORM.DIST(x, mean, sd, cumulative)
LOGNORM.INV(probability, mean, sd)
LOGNORMDIST(x, mean, sd, cumulative)
LOGNORMINV(probability, mean, sd)
LOWER(text)
LT(num1, num2)
LTE(num1, num2)
MATCH(lookupValue, lookupArray, matchType)
MAX(number1, [number2], ...)
MAXA(number1, [number2], ...)
MEDIAN(number1, [number2], ...)
MID(text, start, number)
MIN(number1, [number2], ...)
MINA(number1, [number2], ...)
MINUS(num1, num2)
MINUTE(serial_number)
MIRR(values, finance_rate, reinvest_rate)
MOD(dividend, divisor)
MODE.MULT(number1, [number2], ...)
MODE.SNGL(number1, [number2], ...)
MODEMULT(number1, [number2], ...)
MODESNGL(number1, [number2], ...)
MONTH(serial_number)
MROUND(number, multiple)
MULTINOMIAL(number1, [number2], ...)
MULTIPLY(factor1, factor2)
NE(value1, value2)
NEGBINOM.DIST(k, r, p, cumulative)
NEGBINOMDIST(k, r, p, cumulative)
NETWORKDAYS(start_date, end_date, holidays)
NOMINAL(rate, periods)
NORM.DIST(x, mean, sd, cumulative)
NORM.INV(probability, mean, sd)
NORM.S.DIST(z, cumulative)
NORM.S.INV(probability)
NORMDIST(x, mean, sd, cumulative)
NORMINV(probability, mean, sd)
NORMSDIST(x, mean, sd, cumulative)
NORMSINV(probability)
NOT(logical)
NOW()
NPER(rate, payment, present, future, type)
NPV(arg1, [arg2], ...)
NUMBERS(arg1, [arg2], ...)
NUMERAL(number, format)
OCT2BIN(number, places)
OCT2DEC(number)
OCT2HEX(number, places)
ODD(number)
OR(logical1, [logical2], ...)
PDURATION(rate, present, future)
PEARSON(data_x, data_y)
PERMUT(number, number_chosen)
PERMUTATIONA(number, number_chosen)
PHI(x)
PI()
PMT(rate, periods, present, future, type)
POISSON.DIST(x, mean, cumulative)
POISSONDIST(x, mean, cumulative)
POW(base, exponent)
POWER(number, power)
PPMT(rate, period, periods, present, future, type)
PRODUCT(number1, [number2], ... )
PROPER(text)
PV(rate, periods, payment, future, type)
QUOTIENT(numerator, denominator)
RADIANS(number)
RAND()
RANDBETWEEN(bottom, top)
RATE(periods, payment, present, future, type, guess)
REFERENCE(context, reference)
REGEXEXTRACT(text, regular_expression)
REGEXMATCH(text, regular_expression, full)
REGEXREPLACE(text, regular_expression, replacement)
REPLACE(text, position, length, new_text)
REPT(text, number)
RIGHT(text, number)
ROMAN(number)
ROUND(number, digits)
ROUNDDOWN(number, digits)
ROUNDUP(number, digits)
RRI(periods, present, future)
RSQ(data_x, data_y)
SEARCH(find_text, within_text, position)
SEC(number)
SECH(number)
SECOND(serial_number)
SERIESSUM(x, n, m, coefficients)
SIGN(number)
SIN(number)
SINH(number)
SKEW(number1, [number2], ...)
SKEW.P(number1, [number2], ...)
SKEWP(number1, [number2], ...)
SLN(cost, salvage, life)
SLOPE(data_y, data_x)
SPLIT(text, separator)
SQRT(number)
SQRTPI(number)
STANDARDIZE(x, mean, sd)
STDEV.P(number1, [number2], ...)
STDEV.S(number1, [number2], ...)
STDEVA(number1, [number2], ...)
STDEVP(number1, [number2], ...)
STDEVPA(number1, [number2], ...)
STDEVS(number1, [number2], ...)
STEYX(data_y, data_x)
SUBSTITUTE(text, old_text, new_text, occurrence)
SUBTOTAL(function_code, ref1)
SUM(number1, [number2], ...)
SUMPRODUCT(array1, [array2], [array3], ...)
SUMSQ(number1, [number2], ...)
SUMX2MY2(array_x, array_y)
SUMX2PY2(array_x, array_y)
SUMXMY2(array_x, array_y)
SWITCH(expression, value1, result1, [value2, result2], [value3, result3], ..., [default] )
SYD(cost, salvage, life, period)
T(value)
T.DIST(x, df, cumulative)
T.DIST.2T(x, df)
T.DIST.RT(x, df)
T.INV(probability, df)
T.INV.2T(probability, df)
TAN(number)
TANH(number)
TBILLEQ(settlement, maturity, discount)
TBILLPRICE(settlement, maturity, discount)
TBILLYIELD(settlement, maturity, price)
TDIST(x, df, cumulative)
TDIST2T(x, df)
TDISTRT(x, df)
TEXT(value, format)
TIME(hour, minute, second)
TIMEVALUE(time_text)
TINV(probability, df)
TINV2T(probability, df)
TODAY()
TRANSPOSE(matrix)
TREND(data_y, data_x, new_data_x)
TRIM(text)
TRUE()
TRUNC(number, digits)
UNICHAR(number)
UNICODE(text)
UNIQUE(arg1, [arg2], ...)
UPPER(text)
VALUE(text)
VAR.P(number1, [number2], ...)
VAR.S(number1, [number2], ...)
VARA(number1, [number2], ...)
VARP(number1, [number2], ...)
VARPA(number1, [number2], ...)
VARS(number1, [number2], ...)
WEEKDAY(serial_number, return_type)
WEEKNUM(serial_number, return_type)
WEIBULL.DIST(x, alpha, beta, cumulative)
WEIBULLDIST(x, alpha, beta, cumulative)
WORKDAY(start_date, days, holidays)
XNPV(rate, values, dates)
XOR(logical1, [logical2], ...)
YEAR(serial_number)
YEARFRAC(start_date, end_date, basis)
ฟังก์ชั่นพิเศษ
FORMDATA(formDefId, primaryKey, fieldName) ในคอลัมน์ "Formula" ที่ Spreadsheet
where:
- formDefId: รหัสแบบฟอร์มต้นฉบับที่มีข้อมูลเพื่อ 'ดึง' จากฟอร์ม
- primaryKey: รหัสข้อมูลที่ขึ้นอยู่กับพูลดาวน์ในสเปรดชีตของคุณซึ่งมีเงื่อนไข WHERE เพื่อค้นหาข้อมูล
- fieldName: รหัสข้อมูลของแบบฟอร์มแหล่งที่จะเติมในคอลัมน์สเปรดชีตนี้ขึ้นอยู่กับค่า 'primaryKey' ข้างต้น
ใช้ฟังก์ชันนี้เพื่อ 'ดึง' และเติมเซลล์สเปรดชีตตามข้อมูลที่มีอยู่ในรูปแบบอื่น
ตัวอย่างเช่นหากต้องการดึงการคำนวณและแสดงค่าจำนวนประชากรหลังจากผู้ใช้เลือกชื่อเมือง (เมนูแบบเลื่อนลง) ให้ใช้ FORMDATA ("city_formId", select_city, "population") โดยที่ 'select_city' เป็นรหัสฟิลด์แรกในสเปรดชีตของคุณ